分析与追踪
这里主要关注两种性能分型。针对阻塞和互斥锁所做的性能分析价值不是特别大,那是针对程序中很小的一部分,例如阻塞情况而做的,所以不太能够看出程序的整体的情况,当然,接下来说明的技巧也可以用在这个上面。
- CPU 层面的
- 内存层面的
通过追踪不仅能程序里发生了什么,还能知道哪些事情没有发生。
- 从 CPU 层面,我们要关注的是程序把大部分时间都耗在哪些函数上面
- 从内存层面,要关注两项指标
- 程序要给堆上面放多少个值,如果这样的值比较多且有效期比较短,那么垃圾收集工作就得花费很长时间才能完成。
- 堆的总大小,能不能少用一些空间
栈追踪
程序发生 panic 时,终端会输出栈调用信息。
微观优化
关注单个函数,让这个函数运行更快,可能要查看 CPU 的使用情况,或堆内存的使用情况分析。
使用 -memprofile 对基准测试生成内存报告
|
|
go tool pprof 可以查看涉及 CPU,内存,以及阻塞的分析文件。
|
|
-alloc_space查看内存分配情况-alloc_objects查看各种内容的数量-inuse_sapce默认选项
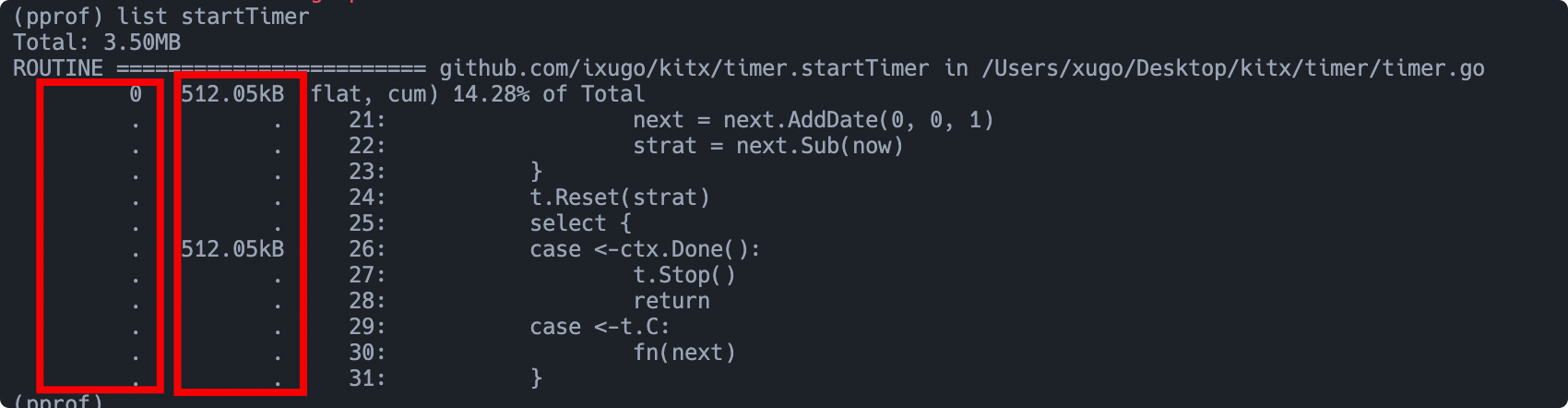
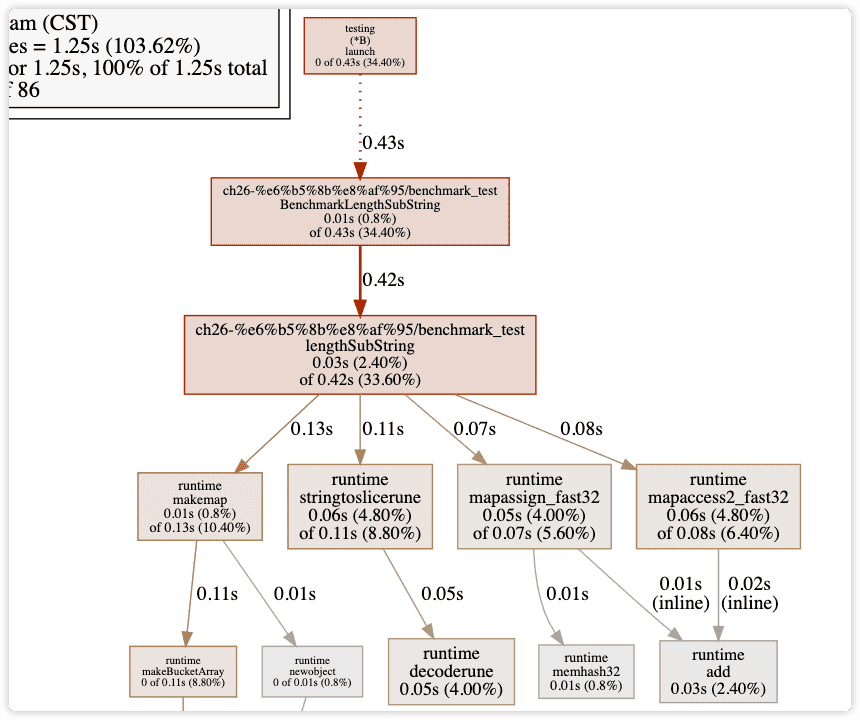
如下图所示,红框有两栏。第一栏 flat 表示该行的内存分配,假如查看的 Profile 是针对 CPU 生成的,则该栏是 CPU 的用量。第二栏 cum 表示从这一行算起,一直沿着调用栈往下累计,看看它本身及调用的代码总共分配了多少内存。
比如下图中的意思是,26 行本身没有分配内存,但是它调用栈往下累计,发生了分配 512.05kb 内存。
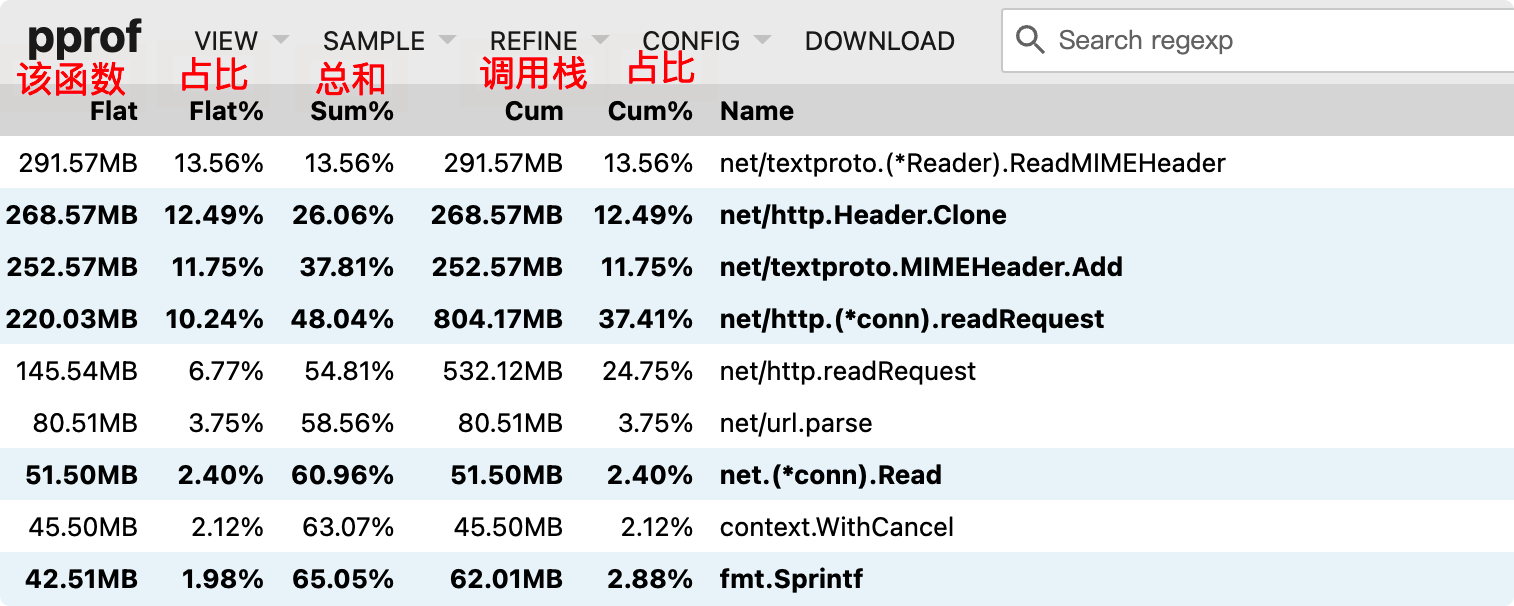
也可以使用网页版
| Flat | 该函数本次运行耗费资源 |
|---|---|
| Flat% | 占总资源的比例 |
| Sum% | 该数据累计耗费资源比例 |
| Cum | 该函数及调用栈总耗费资源 |
| Cum% | 比例 |
| Name | 函数名 |
| 资源 | - |
|---|---|
| inuse_spce | 已分配尚未释放的内存 |
| inuse_objects | 已分配但尚未释放的对象数量 |
| alloc_space | 分配的内存总量 |
| alloc_objects | 分配的对象总数 |
|
|
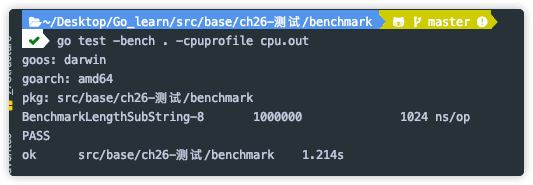
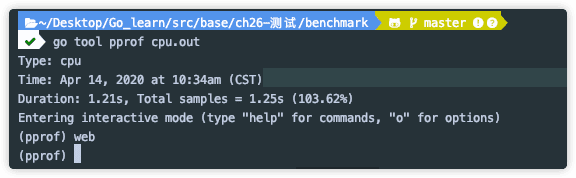
根据图中显示, 哪一块最消耗性能, 针对修改, 使用 pprof 继续进行测试, 以完成性能优化
宏观优化
查看程序调度信息
每 1000 毫秒生成一份调度信息
|
|
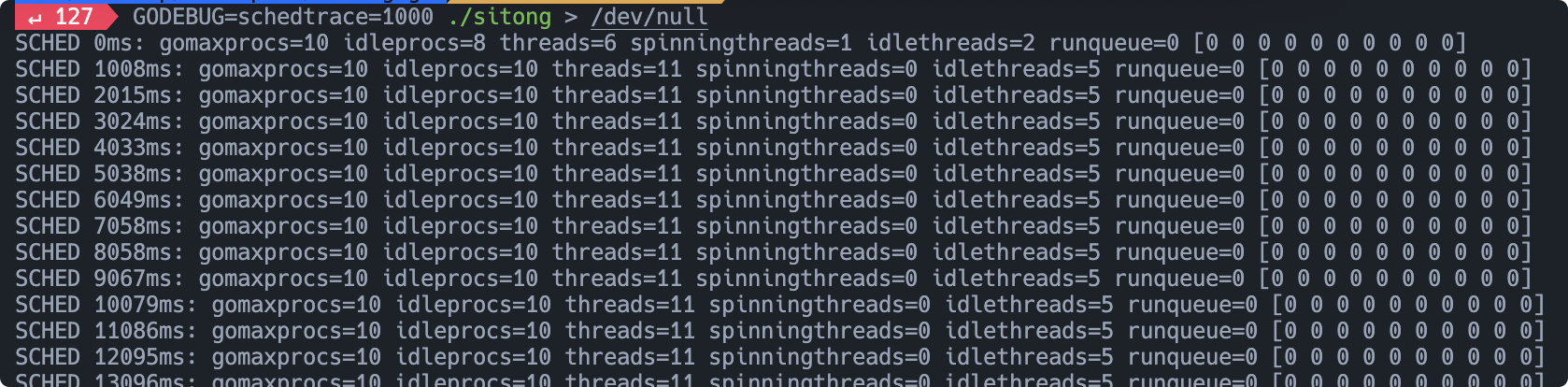
终端会输出正在运行的跟可运行的 goroutine。
- 第一栏是追踪信息的时刻
- 第二栏是有多少个 procs可以使用
- 第三栏闲置的 procs 数量
- 第四栏有多少操作系统级别的线程
- 第五栏
spinningthreads,指的是某个 procs 发现自己一直没事做,所以纵向从别处拿一点儿任务过来,或者就是想让自己在这里空转,防止系统把自己给切换掉 - 第六栏是闲置的系统级线程
- 第七栏是全局运行队列
- 最后是本地运行队列,方括号的每个数字都表示一个逻辑处理器(procs)
给系统增加负载做测试
|
|
如果发生了 goroutine 泄露,那么这些 goroutine 就会进入 waiting 状态,于是我们可以看到全局运行队列与局部队列里的数字就会不断增长。相反如果任务完成,这些数字都会降到 0,说明服务器是很健康的,并没有泄露什么。
查看程序垃圾收集信息
每次垃圾收集打打印一条追踪信息
|
|
gc 1和gc 2… 分别表示第几次垃圾收集- 第二栏表示在生成这条信息时,程序已经运行了多长时间
- 第三栏表示为了完成这次垃圾收集工作,使用了多少 CPU 资源,图中为 0%,说明任务完成的相当快
- 第四栏显示了垃圾收集的三个阶段所花的时间,比如
0.022+0.75+0.035是 STW + Concurrent +STW,两个 STW 加起来不应该超过 100 微秒(0.1 毫秒),如果堆正在膨胀,那么偶尔可能会超过这个值,但不应该频繁发生。我们要关注的是 Concurrent 实际经过时间。 - 第四栏是 CPU 所花的时间,最左边和最右边和上面一样,也是 STW 所花的时间,但它将中间 Concurrent 分成了三个小的部分,这里重点是检查两个 STW 所花的时间。
- 第五栏,如果你怀疑程序有内存泄露问题,那只能通过这个地方来判断。
4->5->1 MB,收集垃圾之前的堆大小,完成收集垃圾后的堆大小,最后是活跃堆的大小。

web 应用引入 pprof 监测性能
|
|
allocs对过去所有的内存分配行为采样,性能调优查看重点此项。block导致阻塞的堆栈跟踪cmdline当前程序通过什么样命令调用的goroutine所有当前 goroutine 的堆栈痕迹heap活跃对象内存分配情况,heap 是以前的老路径,allocs 是1.11 加进来了新路径。
pprof 会注册到net/http 包默认的服务上,建议单独开一个专门 pprof 的服务,端口不要暴露到公网。
分析正在运行的 Go 程序 CPU
这跟 heap 方面的数据有点区别,那个只需要根据以往的堆数据就能统计出来。但 CPU 方面的不同,要想得到有效的报告,必须给程序增加负载,默认的标准中,在生成 CPU 报告时,需要让程序运行 30 秒,以便收集足够量的数据。
如果你想自定义时间
|
|
分析 CPU
|
|
另一种办法做性能分析
除了命令行 go tool pprof ,还有另一种办法做性能分析。
程序会向标准输出端输出一份分析报告。 注意: 与没有做性能分析时相比,这次的程序花的时间会长一些。
|
|
|
|
有时,你会发现大部分性能消耗在操作系统调用上,profile 没能发挥作用,试试 trace。
用 Tracer 追踪程序运行情况
做 trace 也有很多种办法:
- 在命令行里执行
- benchmark 的时候增加 -trace 选项
- 标准库里的函数
有时候我们要看的不是程序发生了什么,而是还没有发生的事情。
|
|
追踪和性能测试不同,它不要求程序必须停下来,只是会把每次函数调用都记录下来,而且会精确到微秒级别。
|
|