栈帧
GMP 中的 G 和 M 非常像,也有一个内存栈。( M 的内存栈是操作系统层面的,大小是 1M )
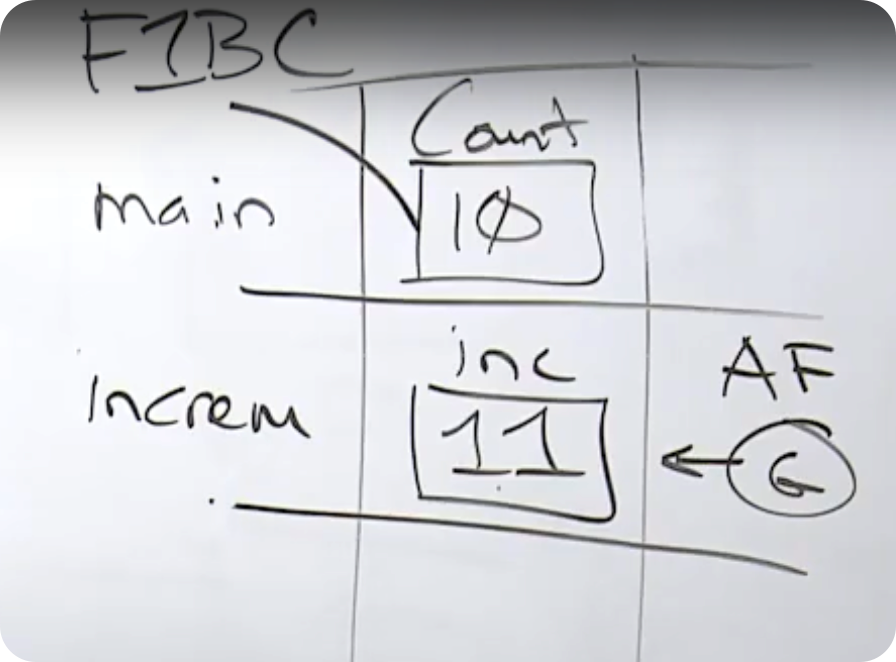
一个 G 的栈大小是 2KB,goroutine 进行函数调用,它会从栈中取出一些内存,我们称为栈帧内存。
|
|
goroutine 只对它所操作的栈帧的内存有直接的访问权,意味者所有的数据都必须在这里,比如声明一个 int 类型的变量,会有 4 个字节的内存就在这个栈帧内。它必须在这个栈帧内,否则 goroutine 就不能访问它。这个栈帧一个非常重要的目的,它在创造一个沙盒,一个隔离层。
参考上面的代码进行一次函数调用,我想让你想到的是,每当进行一次函数调用,真正在做的是跨域了一个程序边界。跨域这个程序边界,意味着将离开当前的栈帧并进入一个新的栈帧,我们需要在新的栈帧内获取数据,如上面程序将变量 a 的值传递给 incr 函数,因为 Go 中的一切都是通过值传递,所以要在数据穿过程序边界时复制一个数据的副本。
你会听到三个术语
- 数据,这是我们工作的对象,数据包含两种类型
- 值,比如变量 a 的整数值 10
- 值地址,指针
在函数 incr 中做出的改变,并没有影响到 main 函数的变量 a,这是函数的隔离性。
优点是不会产生副作用,变量在"“沙盒"中改变,不影响执行环境之外的任何东西,这非常重要!
缺点是在程序中有多个数据副本,值传递是没有效率的,可能会导致代码更加复杂,甚至性能问题。
|
|
记住这句话,在 Go 中一切都是值传递。有人说上面的代码是引用传递,其实不是的。
按值传递意味着跨域程序边界时,会对数据进行复制。在上面的代码中,我们正在复制和传递的数据,不是一个值,而是一个地址。为了让程序能够访问"沙盒"之外的东西,它必须执行对地址的读取。goroutine 只有对栈帧的直接内存访问,如果你想让 goroutine 能够访问其它内存,必须将该内存位置的地址分享给它。
如果多个 goroutine 同时通过指针去访问/修改变量 a,会造成数据竞争。函数式编程试图通过完全不给你指针语义来减少副作用,但是值语义的代价是数据的低效率。后面我们将讨论什么时候使用指针语义,什么时候使用值语义。
优点是解决了效率问题,每个人都可以改变它。代价是副作用和更多的工作 ,需要确保我们没有破坏数据,或者事情不会在幕后被改变。
我们要充分利用语言的各个方面,有助于减轻内存管理的认知负担。
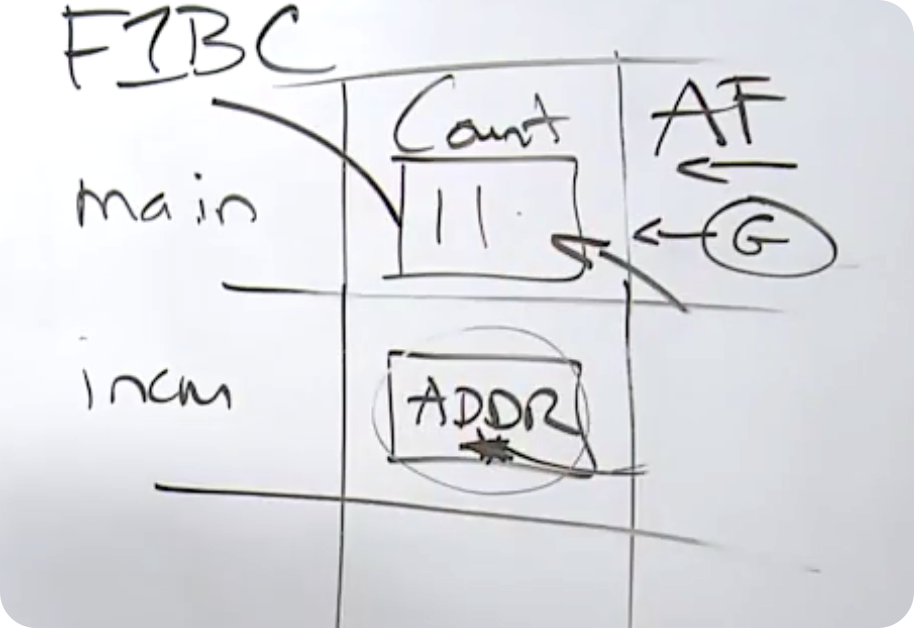
注意 : 当 main 函数进行另一个函数调用时,会发生什么? 它需要另一个栈帧,它会清理掉活动帧以下的内存,重复使用。
逃逸
我们通常会有一些工厂函数,用来创建结构体对象。注意,在 Go 中没有构造函数,它隐藏了成本,我们所拥有的是我称之为工厂函数的东西,工厂函数是一个可以创建一个值的函数。初始化它,并返回给调用者。这对于可读性来说是很好的,它没有隐藏成本。我们可以读懂它,并且在结构上有助于简化。
|
|
在上面的示例中,有两个版本的创建用户,注意它们的返回类型。
createUseV1 是值语义的,它返回数据的副本,不会有任何副作用。
createUserV2 是指针语义的,这次不是在制作一个值的副本,要做的是拷贝值的地址。要知道栈帧是复用的,这块内存用完就会丢掉。我们好像引用了一个会被销毁的地址,这非常可怕。但实际上,编译器非常强大,它能够进行静态代码分析,将确定一个值是否被放在栈上,还是逃逸到堆中。
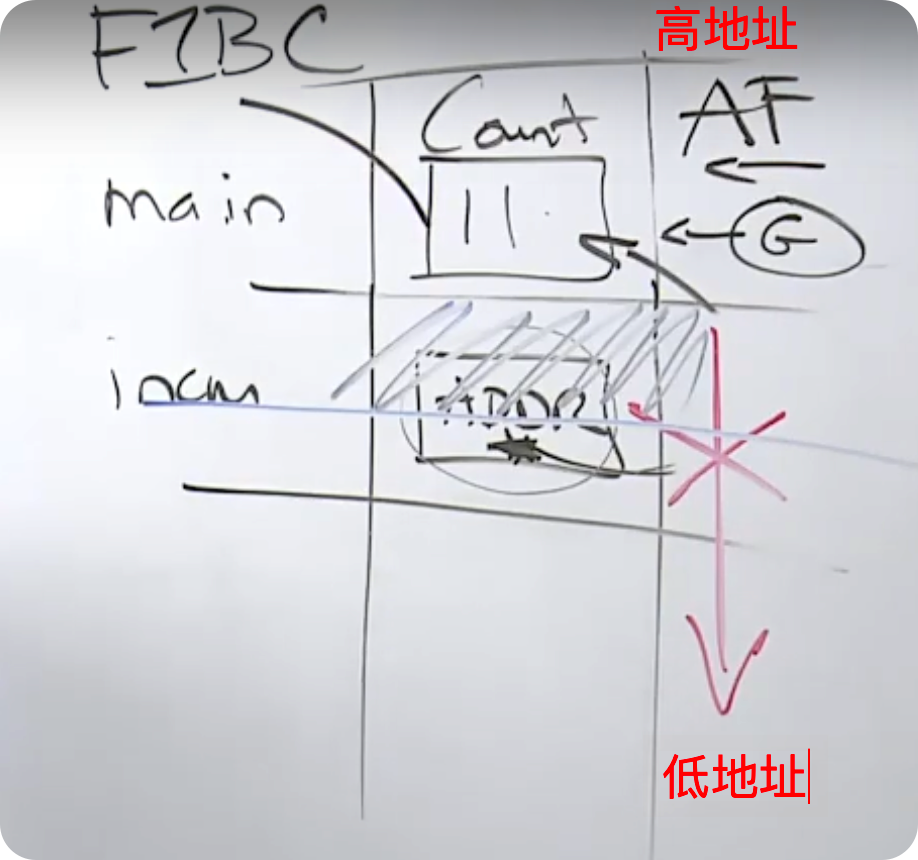
充分利用栈是非常非常快的,栈是自我清洁的。这意味着,垃圾处理器甚至不会介入,直到一个值逃出栈,并在堆上结束。
为什么栈是自我清洁的? 参考上面绘图,从栈帧返回到上面时,内存会被单独留在栈中,并在下行时进行清理,所以垃圾处理器并不需要参与。栈可以为我们提供大量的性能,因为内存是已经分配好的,而且它可以自我清理。
我们应该尽力利用值语义,并将值保留在栈中,不仅仅是因为隔离和不变性的带来减少副作用的好处,而且在很多情况下还能带来更好的性能,因为一旦有东西被分配到堆上,垃圾处理器就必须参与进来。
另外,指针在可读性上,有一个指导原则。
在构造过程中使用指针语义,现在我们使这段代码更难读了。在构造过程中,不要使用指针语义,希望你在构造过程中使用值语义,仅在调用处使用指针语义。除非你想直接返回(return &user{})。
再次提醒,如果你将一个变量的生命作为一个指针开始,你就会失去可读性。
|
|
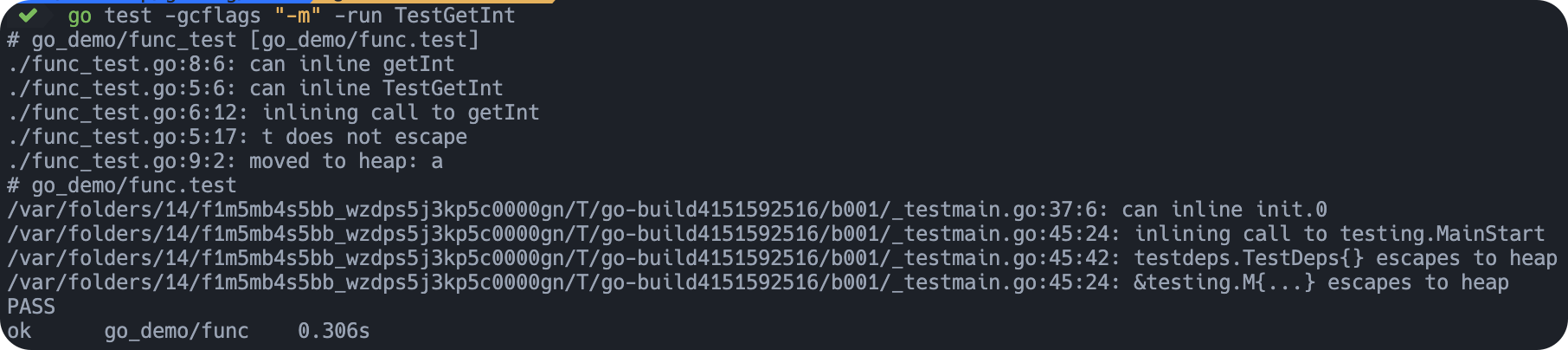
生成逃逸分析报告
|
|
当你在 go build 中使用 gcflags 时,你将得到的不是一个二进制文件,而是逃逸分析报告。
内存分配
如果在编译时,编译器不知道一个值的大小,它必须立即在堆上构建,因为栈帧不是动态的,都是在编译时确定尺寸,所以编译时不知道值的大小,就不能放在栈里。
我们知道 Go 中的栈是非常非常小的,操作系统的栈大约是 1MB,而 Go 栈是 2KB。如果有一个 goroutine 进行大量的函数调用,并最终耗尽了栈空间,会发生什么呢? Go 所做的是它有连续栈,它会分配一个更大的栈,比原来的栈大 25%,然后,把所有的栈帧复过来。
垃圾处理器
一旦在堆上进行了内存分配,它就会停留在那里,直到被回收。
我们想要的是最小的堆,减少内存使用。那么怎样才能得到最小的堆?