结构体
自定义类型。
定义结构体
1
2
3
4
5
6
7
8
|
type Employee struct {
ID int
Name string
Address string
DoB time.Time
}
var dilbert Employee
|
结构体类型的零值是每个成员都是零值。
使用 . 操作符可以对每个成员赋值 , 取地址
指针也可以直接使用 . 操作符, 相当于 (*p).param
如果结构体成员名字是以大写字母开头的,那么该成员就是导出的;可以被 json 序列化
一个聚合的值 , 不能包含它本身, 同样适用于数组, 所以 a 结构体不能嵌套 a 结构体 , 但可以包含 *a , 这样可以创建递归的数据结构, 比如链表和树
例题 使用二叉树排序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
type tree struct {
value int
left, right *tree
}
// Sort sorts values in place.
func Sort(values []int) {
var root *tree
for _, v := range values {
root = add(root, v)
}
appendValues(values[:0], root)
}
// appendValues appends the elements of t to values in order
// and returns the resulting slice.
func appendValues(values []int, t *tree) []int {
if t != nil {
values = appendValues(values, t.left)
values = append(values, t.value)
values = appendValues(values, t.right)
}
return values
}
func add(t *tree, value int) *tree {
if t == nil {
// Equivalent to return &tree{value: value}.
t = new(tree)
t.value = value
return t
}
if value < t.value {
t.left = add(t.left, value)
} else {
t.right = add(t.right, value)
}
return t
}
|
匿名结构体变量与类型转换
这些字面意义上的类型真的很方便,比如,在一个网络 API 上进行反序列化,你需要一些类型信息,但是给它命名不一定好,因为这只需要在这一个地方使用,而我们不想给只在一个地方使用的东西命名,那将是一种污染。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
func main(){
// 声明名为 e1 的变量
var e1 struct{
flag bool
counter int64
}
e2 := struct{
flag bool
counter int64
}{
flag: true,
counter: 4,
}
// ...
}
|
bill 和 alice 的字段相同。赋值不会做隐式类型转换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
type bill struct{
flag bool
counter int64
}
type alice struct{
flag bool
counter int64
}
func TestSameStruct(t *testing.T) {
b := bill{counter: 11}
a := alice{counter: 22}
// 强制类型转换
a = alice(b)
t.Log(a, b)
c := struct {
flag bool
counter int64
}{
counter: 33,
}
// 无序类型转换
a = c
t.Log(a, c)
}
|
结构体字面值
按定义顺序赋值, 通常用于包内或较小的结构体,
1
2
|
type Point struct{ X, Y int }
p := Point{1, 2}
|
更常用的写法 , 顺序不重要 , 未赋值的成员默认零值
1
|
anim := gif.GIF{LoopCount: nframes}
|
作为函数参数
结构体可以作为函数的参数和返回值。
考虑效率的话, 可以考虑使用指针传入和返回
1
2
3
|
func Bonus(e *Employee, percent int) int {
return e.Salary * percent / 100
}
|
在 Go 语言中, 所有的函数参数都是值拷贝 , 函数参数不再是函数调用时的原始变量
结构体比较
如果所有成员可以比较, 则相同类型的结构体可以使用 == 或 != 比较
注意, 每个结构体都是不同类型, 哪怕成员属性一样;
可比较的结构体类型和其他可比较的类型一样,可以用于map的key类型。
不可比较类型 : since map function
当结构体中包含 slice 或 map 时, 可以使用 reflect.DeepEaual 比较
结构体嵌套 和 匿名成员
匿名成员的数据类型必须是命名的类型或指向一个命名的类型的指针。
匿名成员可以直接访问其叶子属性及方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
type Point struct{
x, y int
}
type Circle struct {
Point
Radius int
}
var c Circle
c.x=8
c.y=8
c.Radius=5
fmt.Printf("%#v\n", c) // # 可以输出 包名/结构体名/成员名
|
不能同时包含两个类型相同的匿名成员, 这会导致命名冲突
匿名成员 序列化
- A结构体成员名与匿名结构体的成员名出现冲突 , 则仅序列化 A结构体成员
- 序列化后匿名结构体的成员与 A 结构体成员是同级
以上两点详情见 json 那篇文章
内存对齐
内存对齐是为了使读写尽可能提高内存的效率。
如果不做内存对齐,一个类型越过了两个边界,那么需要一到两个操作来写它,这并不高效。
编译器会将不同的类型分配到合适的内存,使它们总是落在边界内。
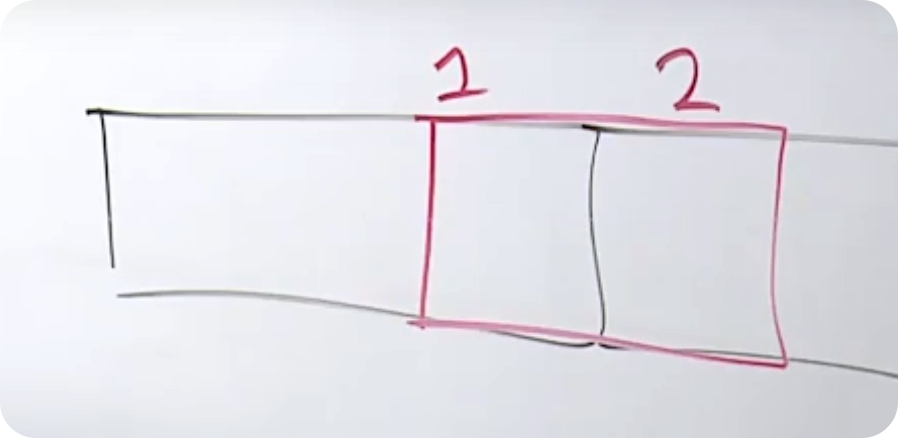
比如现在有 bool,int16,int32 三种类型。
1
2
3
4
5
|
type T struct{
a bool
b int16
c int32
}
|
a 占用 1 个字节,b 占用 2 个字节,c 占用 4 个字节。
为了对齐边界,内存必须是 2 的倍数,即 a 占用 2 个字节,多的一个字节会自动填充跳过。
2+2+4 = 8,字段 a 会填充 1 个字节
如果 b 是 int 32 类型呢?
4+4+4 = 12,内存必须是 4 的倍数,字段 a 会填充 3 个字节
如果 b 是 int64 类型呢?
8+8+8,内存必须是 8 的倍数,字段 a 会填充 7 个字节,字段 c 会填充 4 个字节
**通过调整字段顺序,可以优化内存,为什么语言不能为你做这个内存对齐? **
你可以控制你的内存布局,根据需要使他们变得更准确,语言的工作不是在背后试图预先为你优化东西。
注意: 除非有一个基准,表明因此占用了太多内存,才应该优化这个结构以减少填充。否则,将语义上相同的字段放在一起,可读性更重要。