这几天,我开发了一个名为 “Horcux” 的程序,它允许将一个文件拆分为任意数量的魂器,然后可以重新组合以恢复原始文件。期间,我了解了很多有关 io.Reader 和 io.Writer 接口的知识,与大家分享。
为什么使用 io.Reader 和 io.Writer? 在 Horcrux 的第一个版本中,做了类似以下的事情来加密文件。
1
2
3
4
5
6
7
8
9
|
func main() {
// plaintext: "this is my file's content"
content, _ := ioutil.ReadFile("myfile")
encryptedContent := encrypt(content)
// ciphertext: "uijt!jt!nz!gjmf(t!dpoufou"
ioutil.WriteFile("myfile.encryped", encryptedContent, 0644)
}
|
小文件超级快。当文件为 1GB 时超级慢。我的目的是加密源文件,而不是将整个文件加载到内存中。这就是 io.Reader 和 io.Writer 发挥作用的地方。
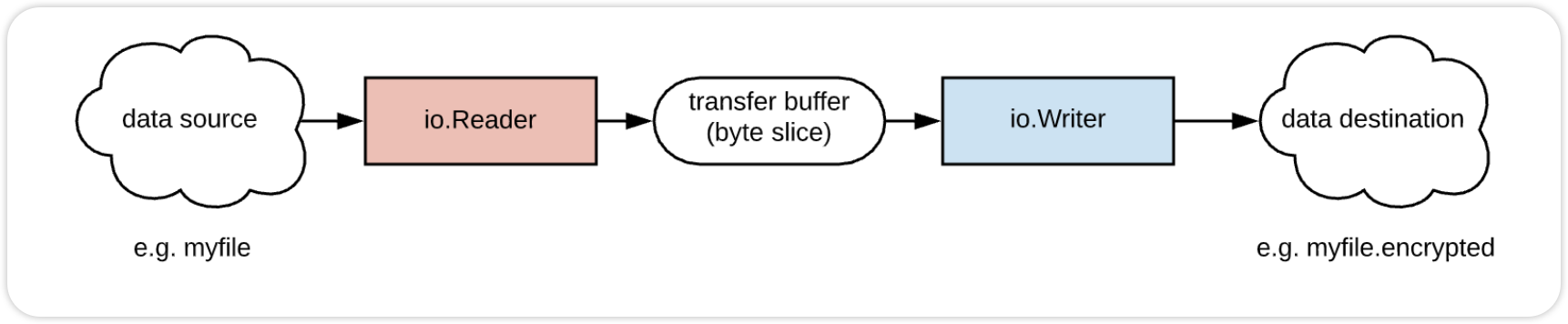
io.Reader 从源读取数据。io.Writer 将内容写入目的地,两个接口是处理流信息的接口。
流式方法有几个好处:
- 用一个小的缓冲区读写数据,不需要将整个文件加载到内存
- 不需要等待整个文件加载好才开始加密,一旦数据读入缓冲区,即可开始写入目标文件。
io.Reader
什么是 io.Reader?
1
2
3
|
type Reader interface {
Read(p []byte) (n int, err error)
}
|
常见的返回错误是 io.EOF,它代表读取结束。
按照惯例,在 Go 中,当函数有多个返回值时,其中一个是 error,如果发生错误,其他值应为零值。但考虑如果读取中途发生错误,应该告诉调用者当前读取了多少字节。
使用 io.Reader
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
func main(){
reader := strings.NewReader("this is the stuff i'm reading")
var result []byte
buf := make([]byte,4)
for {
n,err := reader.Read(buf)
result = append(result, buf[:n]...)
if err != nil {
if err == io.EOF {
break
}
log.Fatal(err)
}
}
fmt.Println(string(result))
}
|
在上面的代码中,创建缓冲区(大小为 4 字节) 并执行循环,在每次循环中调用读取器上的 Read 方法,并使用第一个返回值来查看已写入多少字节。最后将这些数据附加到结果中,如果出现 EOF 错误,跳出循环。\
注意有一个点是先处理数据,再处理错误。返回 (0,nil) 并不意味着没有更多内容可读,可能是正在等待底层源返回更多的数据。
实现 io.Reader
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
type myReader strcut{
content []byte
position int
}
func (r *myReader) Read(buf []byte) (int,error) {
remainingBytes := len(r.content) - r.position
n := min(remainingBytes,len(buf))
if n == 0 {
return 0, io.EOF
}
copy(buf[:n], r.content[r.position:r.position+n])
r.position += n
return n,nil
}
|
在这里,创建一个结构体,包含要读取的内容 content 字段,以及用于跟踪读取位置的 position 字段。 将源数据填充缓存区并防止溢出。
注意,当没有更多内容可读取时,返回 (0,io.EOF) ,从而避免调用者对 Read 方法进行不必要的调用。
编写 io.Readers
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
type augmentedReader struct{
innerReader io.Reader
augmentFunc func([]byte) []byte
}
// replaces ' ' with '!'
func bangify(buf []byte) []byte {
return bytes.Replace(buf, []byte(" "), []byte("!"), -1)
}
func (r *augmentedReader) Read(buf []byte) (int, error) {
tmpBuf := make([]byte, len(buf))
n, err := r.innerReader.Read(tmpBuf)
copy(buf[:n], r.augmentFunc(tmpBuf[:n]))
return n, err
}
func BangReader(r io.Reader) io.Reader {
return &augmentedReader{innerReader: r, augmentFunc: bangify}
}
func UpcaseReader(r io.Reader) io.Reader {
return &augmentedReader{innerReader: r, augmentFunc: bytes.ToUpper}
}
...
package main
import (
. "augment"
...
)
func main() {
originalReader := strings.NewReader("this is the stuff I'm reading")
augmentedReader := UpcaseReader(BangReader(originalReader))
result, err := ioutil.ReadAll(augmentedReader)
if err != nil {
log.Fatal(err)
}
fmt.Println(string(result)) // THIS!IS!THE!STUFF!I'M!READING
}
|
这一个增强包,它导出一些可组合的读取器函数。每个函数都接受一个 io.Reader,并返回一个 io.Reader。但内部 io.Reader 的输出由外部 IO 增强。在本例中,将 " " 与 ! 交换。
使用 io.Writer
1
2
3
4
|
func main() {
writer := os.Stdout
writer.Write([]byte("hello there\n"))
}
|
实现 io.Writer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
type myWriter struct {
content []byte
}
func (w *myWriter) Write(buf []byte) (int, error) {
w.content = append(w.content, buf...)
return len(buf), nil
}
func (w *myWriter) String() string {
return string(w.content)
}
func main() {
writer := &myWriter{}
writer.Write([]byte("hello there\n"))
fmt.Println(writer.String()) // "hello there\n"
}
|
在 Write 方法中仅获取缓冲区并将其附加到其内部内容。我们还给它一个String方法来告诉我们到目前为止它写了什么。碰巧我们在这里实现了 bytes.Buffer 的精简编写器版本。
参考
本文翻译于 Golang IO Cookbook