鲲鹏弹性云服务器运行网络爬虫(上)
零
系统:ubuntu 18.04
爬虫:pyspider
容器引擎:docker
服务器:鲲鹏弹性云KC1
记录全部过程
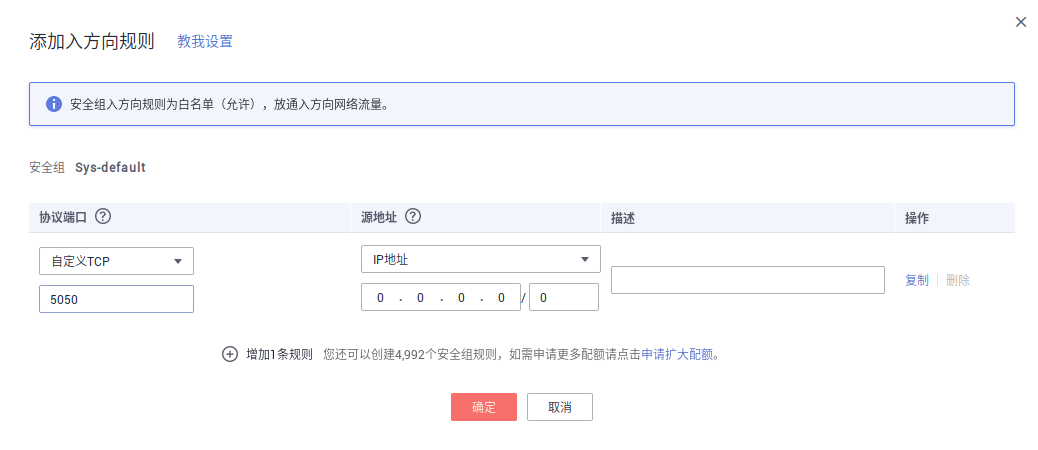
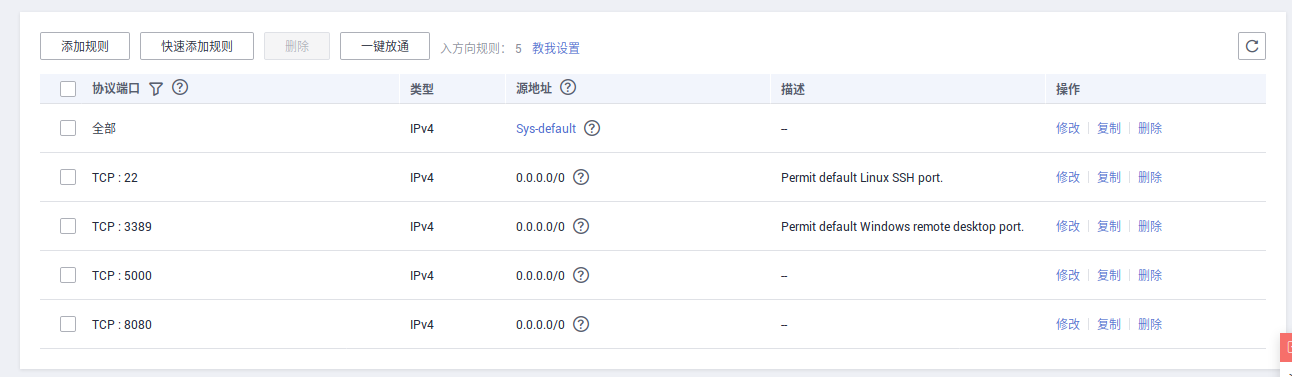
一 开放5000端口
【控制台】-【弹性云服务器ECS】-【安全组】-【配置规则】-【添加规则】
二 Python 环境
分别是 依赖库, python3, pip包管理
1
2
3
4
5
|
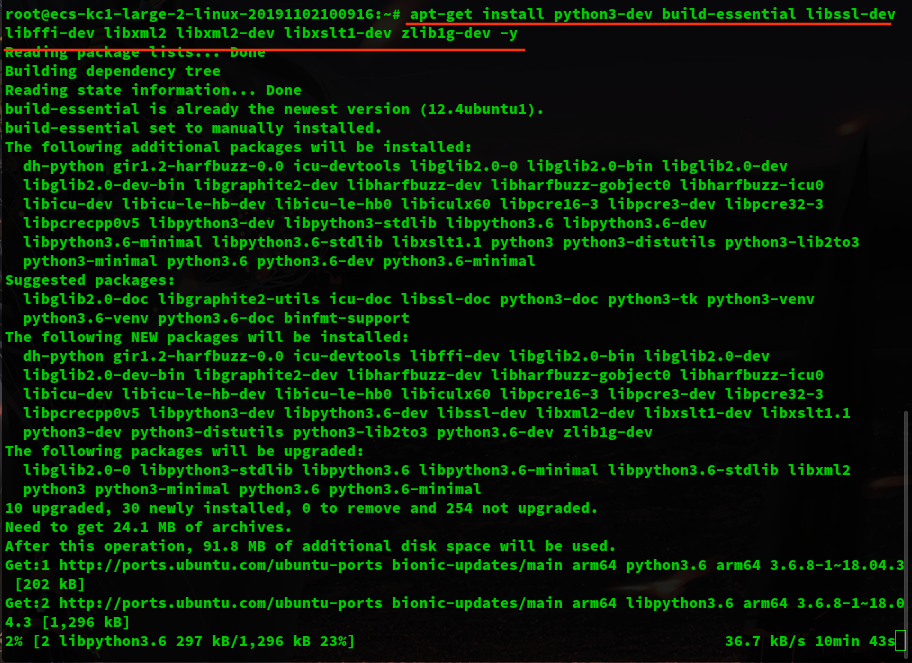
sudo apt-get install python3-dev build-essential libssl-dev libffi-dev libxml2 libxml2-dev libxslt1-dev zlib1g-dev
sudo apt-get install python3
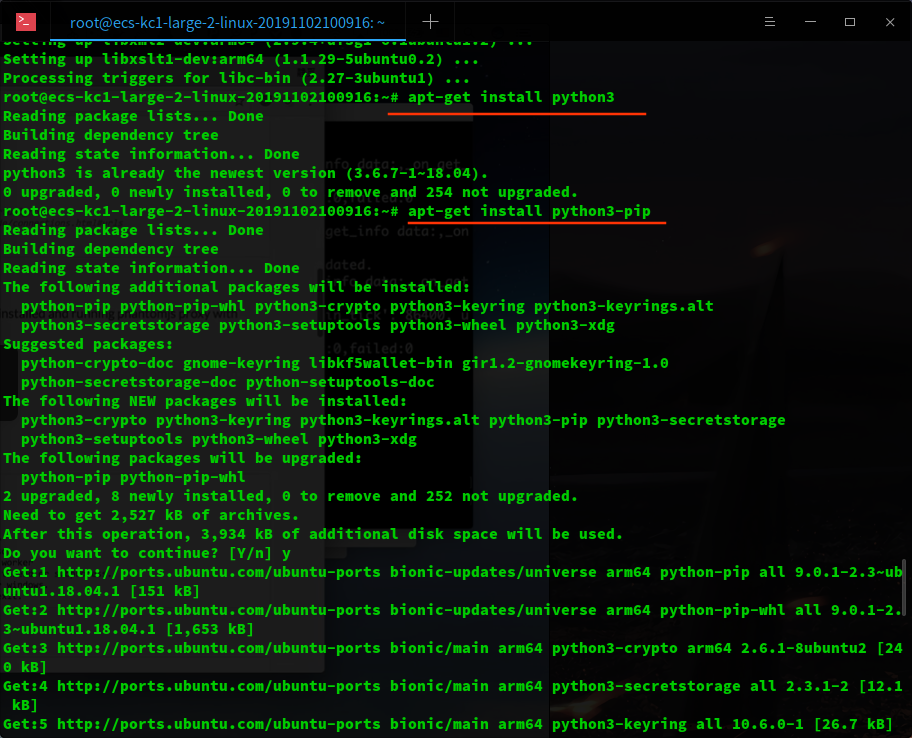
sudo apt-get install python3-pip
|
二 pyspider 安装
pyspider是一个爬虫架构的开源化实现。主要的功能需求是:
- 抓取、更新调度多站点的特定的页面
- 需要对页面进行结构化信息提取
- 灵活可扩展,稳定可监控
去重调度,队列,抓取,异常处理,监控等功能作为框架,提供给抓取脚本,并保证灵活性。最后加上web的编辑调试环境,以及web任务监控,即成为了这套框架。
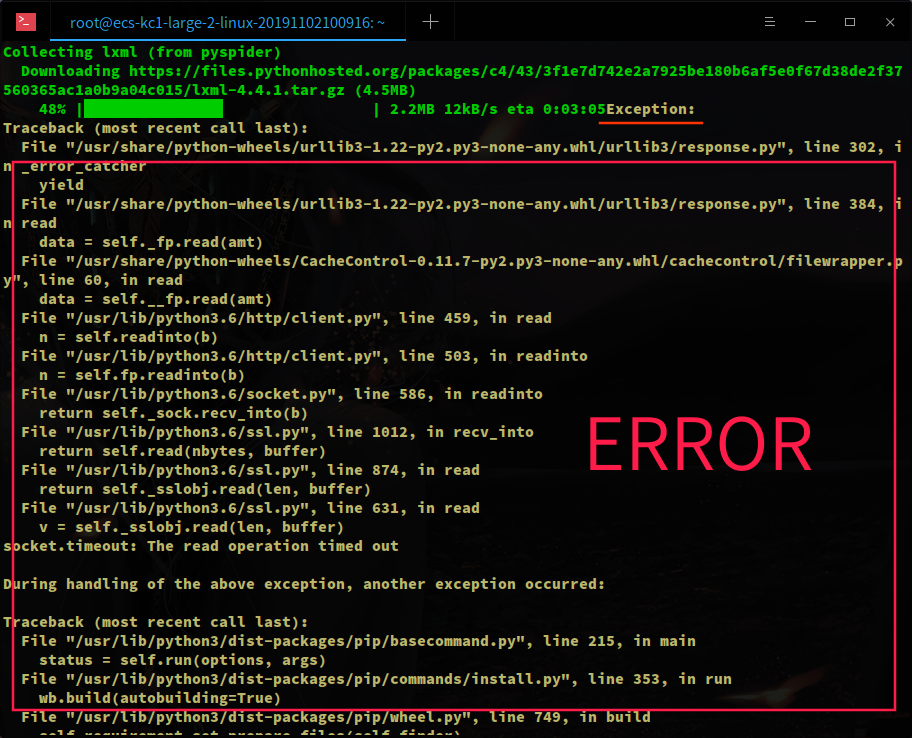
在安装的过程中遇到了错误,期间总共遇到过 3 次异常,超时错误,退出异常等,按照步骤一步步来,会好起来的。
执行下列命令,再次安装 pyspider,耐心等待几分钟,查看版本
1
2
|
apt-get install libcurl4-openssl-dev
pip3 install pyspider
|

三 phantomjs 安装
PhantomJS 是一个基于 webkit 的 javascriptAPI。它使用 QtWebKit 作为它核心浏览器的功能,使用webkit来编译解释执行JavaScript代码。任何你可以在基于 webki t浏览器做的事情,它都能做到。PhantomJS 的用处可谓非常广泛,诸如网络监测、网页截屏、无需浏览器的Web 测试、页面访问自动化等。
1
2
3
|
wget https://bitbucket.org/ariya/phantomjs/downloads/phantomjs-2.1.1-linux-x86_64.tar.bz2
tar -jxvf phantomjs.tar.bz2
ln -s /usr/local/phantomjs-2.1.1-linux-x86_64/bin/phantomjs /usr/bin/phantomjs
|
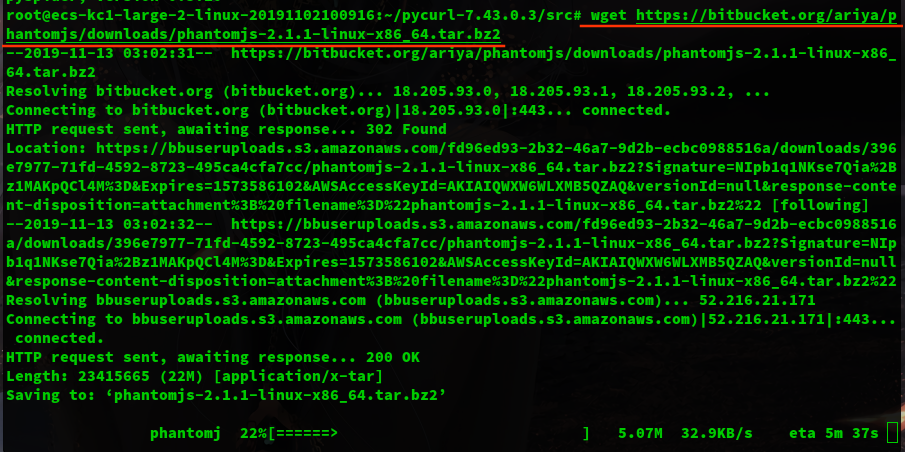

环境已经配置完毕,运行一下试试
四 异常
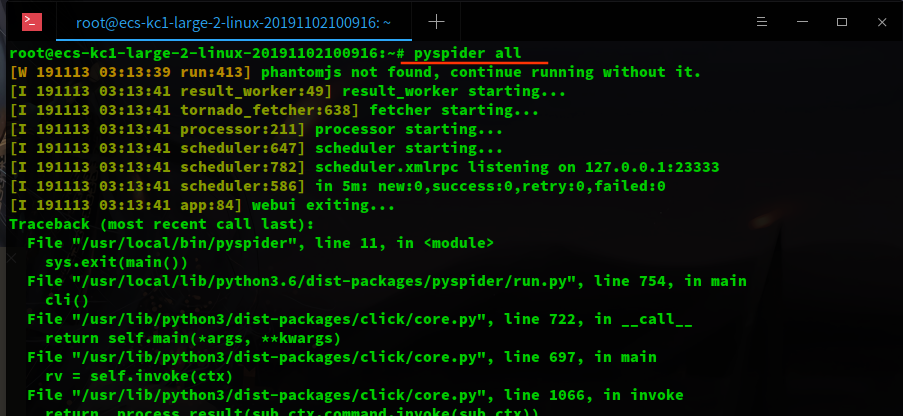
最会,应该还会遇到一个生命中的 BUG,本文可以说涵盖了安装过程的大部分问题
主要错误信息是
1
2
3
4
|
File "/usr/local/lib/python3.6/dist-packages/wsgidav/wsgidav_app.py", line 118, in _check_config
raise ValueError("Invalid configuration:\n - " + "\n - ".join(errors))
ValueError: Invalid configuration:
- Deprecated option 'domaincontroller': use 'http_authenticator.domain_controller' instead.
|
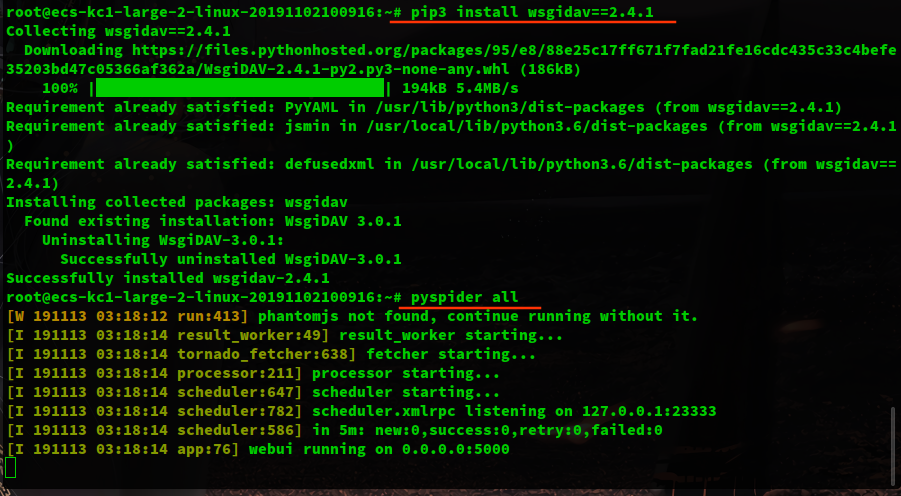
执行以下命令
1
2
3
|
pip3 install wsgidav==2.4.1
# 终于启动
pyspider all
|
五 在本地电脑输入 ip:5000
预告: 下一篇博文,正式开始网络爬虫,将以小白的视角来记录,并不会晦涩难懂
鲲鹏弹性云服务器运行网络爬虫(下)
零
系统:ubuntu 18.04
爬虫:pyspider
服务器:鲲鹏弹性云KC1
记录全部过程
一 设置登录账号和密码
创建 db.json 文件,用于设置登录账号和密码
不要在 data 文件夹内创建 db.json,data 是 pyspider 第一次启动时创建的文件,保存着数据信息,所以最好每次运行都在 data 的父目录或者指定 data 目录位置,以保证旧数据存在。
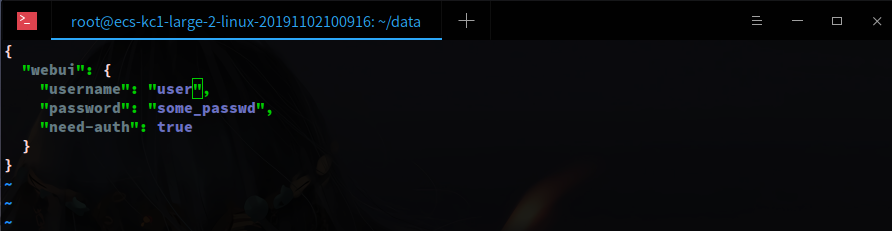
执行命令启动
1
|
pyspider --config db.json all
|
在本地电脑,打开浏览器,输入服务器的ip地址:5000,即弹出登录对话框,输入之前设置的用户名和密码
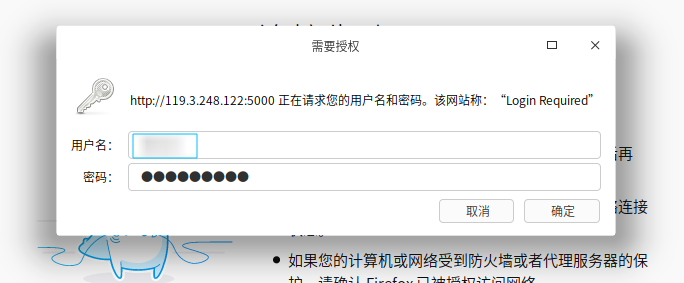
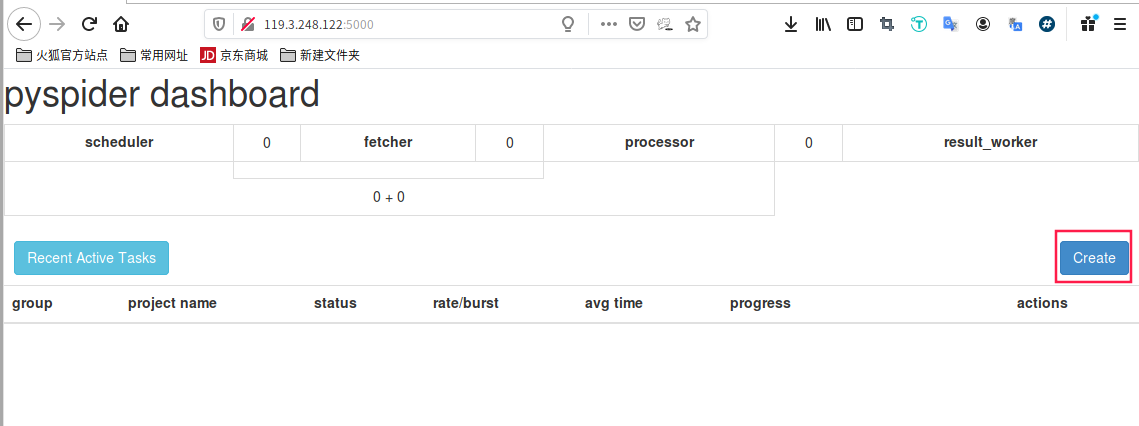
二 创建第一个爬虫
简单的操作,见图
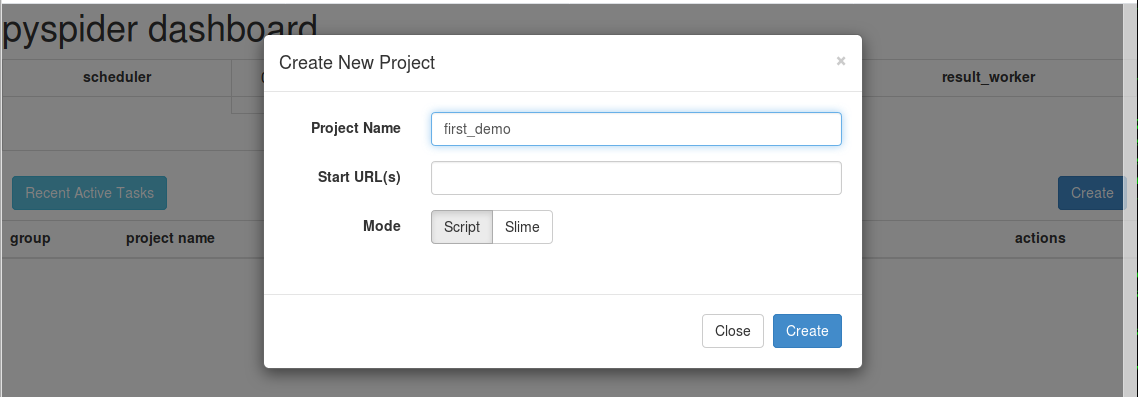
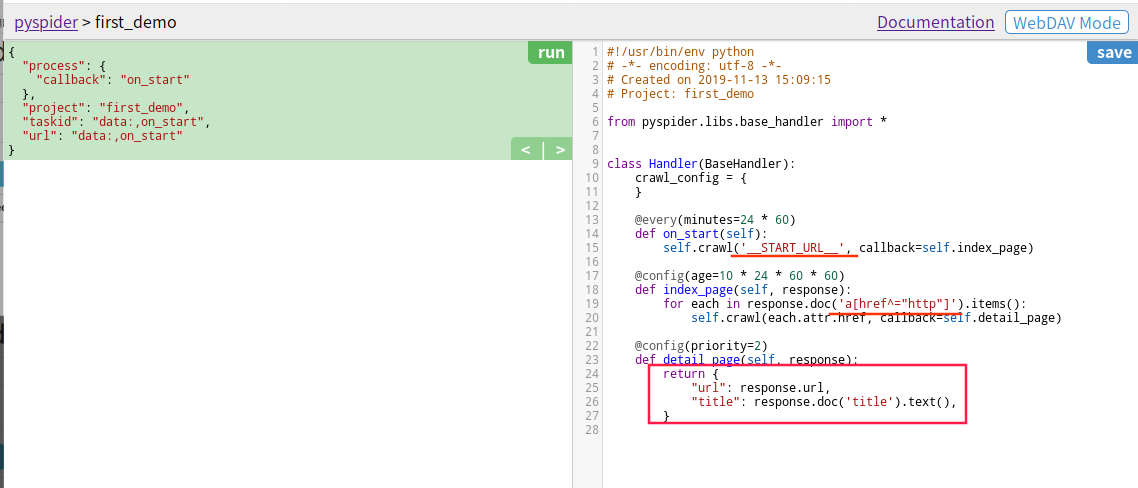
创建之后,自动生成基础代码,15 行横线处是待爬取的首页链接,19 行是查找详情页,也就是首页面的所有跳转链接,最后的方框则是返回的结果
三 实战
爬取网页:http://quotes.toscrape.com/
信息:名言内容,作者,标签
查看网页信息,每一句名言都是一个div,class=quote, 这里关键字是 quote
1
2
3
4
5
6
7
8
9
|
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://quotes.toscrape.com/', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
results = []
for each in response.doc('.quote').items():
pass
|
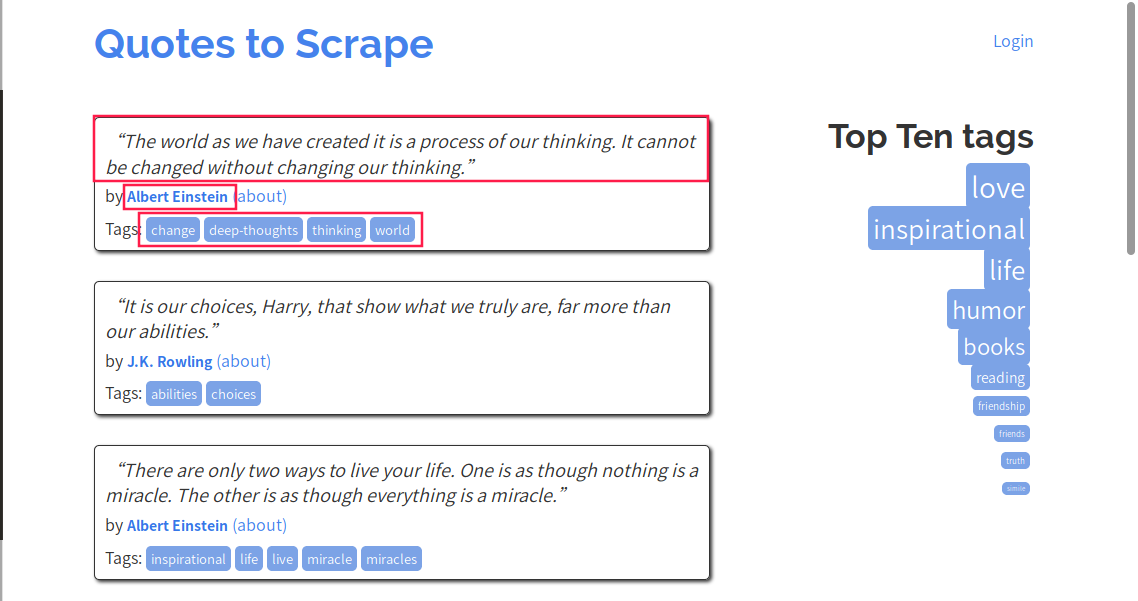
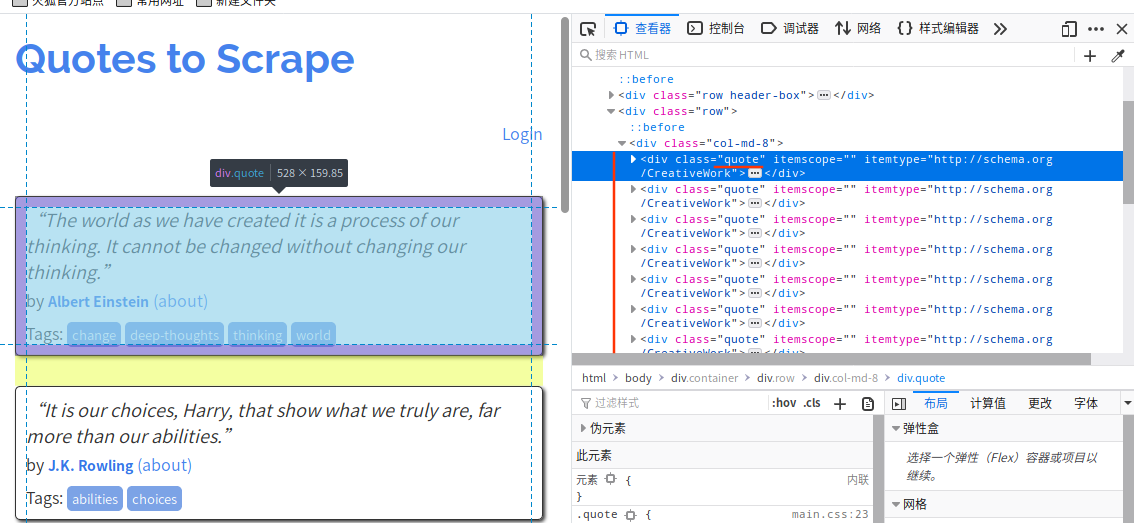
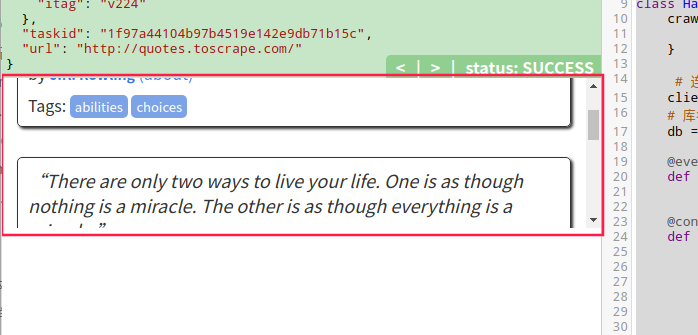
F12 查看元素,元素选择器(图片中红标1)选择作者名,在右边代码栏可见该标签,其它标签属性有 itemprop="author" ,以此类推
代码可以这样写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# 名言结果集
results = []
# 循环每一句名言
for each in response.doc('.quote').items():
# 名言
comment = each.find('[itemprop="text"]').text()
# 作者
author = each.find('[itemprop="author"]').text()
# 标签
tags = each.find('.tags .tag').items()
# 标签结果集
tagList = []
for tag in tags:
tagList.append(tag.text())
# 将查询到名言封装到名言结果集
results.append({
"comment": comment,
"author": author,
"tagList": tagList
})
|
结果

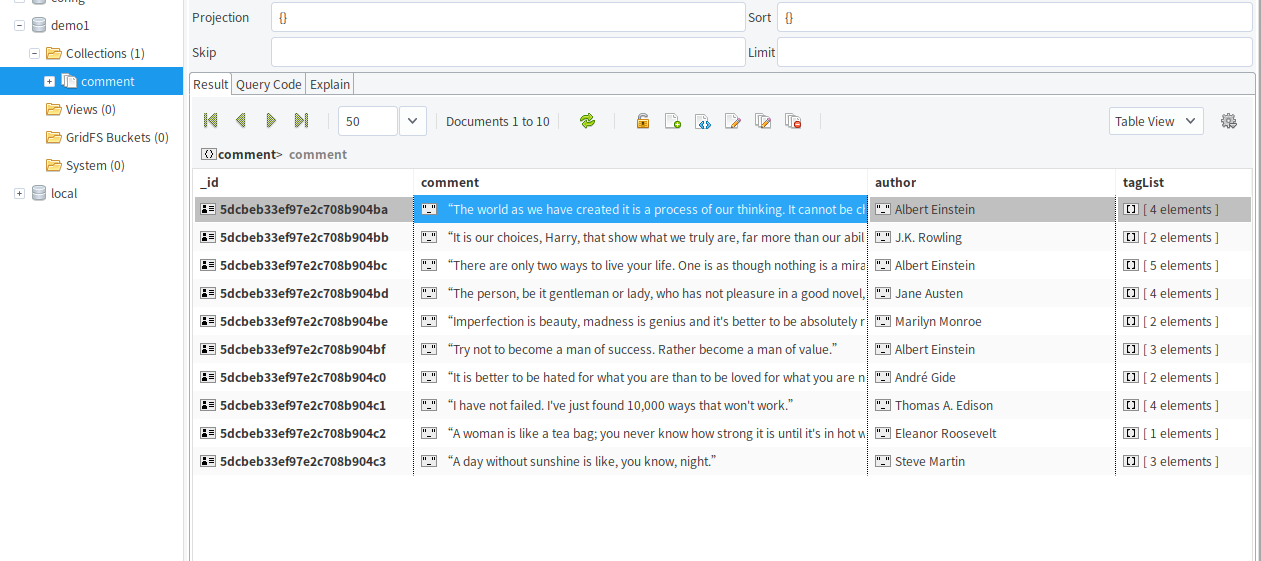
四 将结果存储到 MongoDB
如何在鲲鹏弹性云部署 MongoDB,见下链
https://bbs.huaweicloud.com/forum/thread-28769-1-1.html
1
安装 pymongo
2
爬虫代码:
1
2
3
4
|
# 连接 mongodb 数据库
client = pymongo.MongoClient('119.3.248.122')
# 库名为 demo1
db = client['demo1']
|
1
2
3
4
5
6
7
8
9
|
# 如果有结果集,调用存储数据库函数
def on_result(self,result):
if result:
self.save_to_mongo(result)
# 存到数据库
def save_to_mongo(self,result):
if self.db['comment'].insert(result):
print('saved to mongo',result)
|
#化鲲为鹏,我有话说# 鲲鹏弹性云服务器运行网络爬虫(下)分页与总结
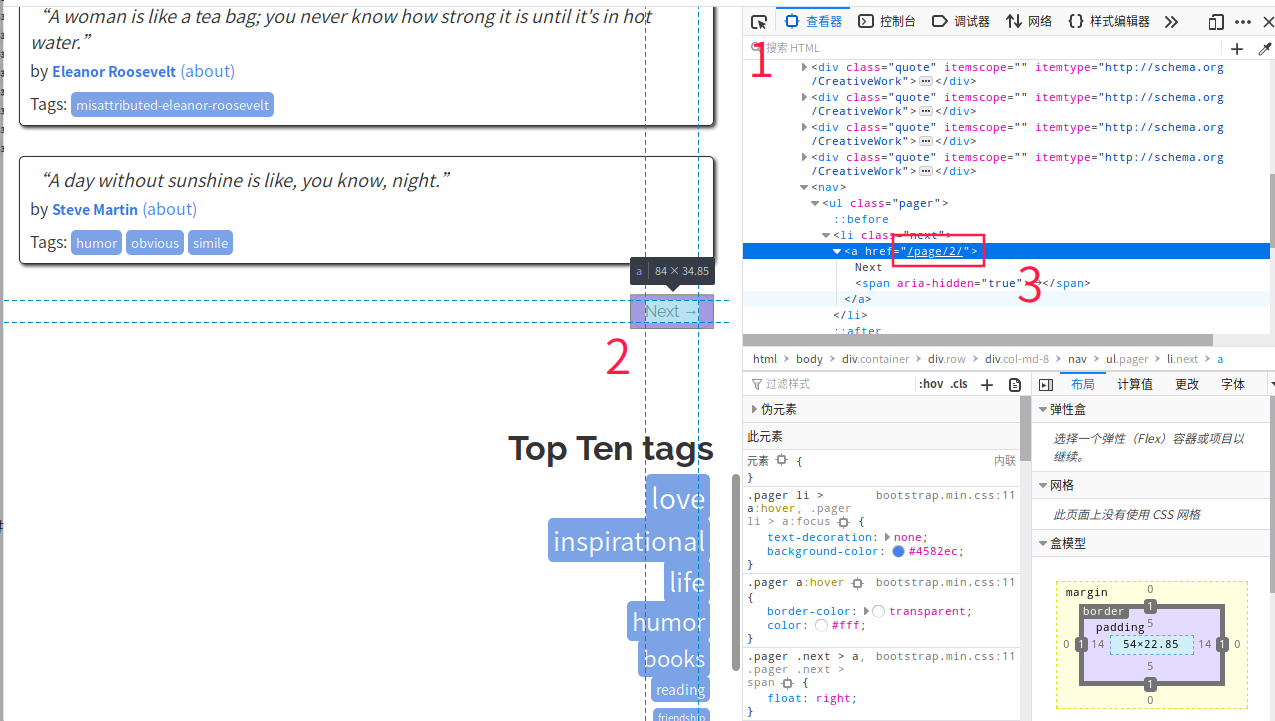
一 分页
通过之前的方法,用选择器点击图标,右侧代码框会自动定位该元素,这里可以看到通过 /page/2/ 以末尾的数字进行分页
获取该链接, 然后递归调用自己一直查询
1
2
|
next = response.doc('.next a').attr.href
self.crawl(next, callback=self.index_page)
|
二 源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2019-11-24 03:27:43
# Project: demo1
from pyspider.libs.base_handler import *
import pymongo
class Handler(BaseHandler):
crawl_config = {
'itag': 'v224'
}
# 连接 mongodb 数据库
client = pymongo.MongoClient('localhost')
# 库名为 trip
db = client['demo1']
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://quotes.toscrape.com/', callback=self.index_page)
@config(age=60)
def index_page(self, response):
self.crawl(response.url, callback=self.detail_page)
next = response.doc('.next a').attr.href
# 递归调用
self.crawl(next, callback=self.index_page)
@config(priority=2)
def detail_page(self, response):
results = []
for each in response.doc('.quote').items():
comment = each.find('[itemprop="text"]').text()
author = each.find('[itemprop="author"]').text()# 作者
# 标签
tags = each.find('.tags .tag').items()
# 标签结果集
tagList = []
for tag in tags:
tagList.append(tag.text())
# 将查询到名言封装到名言结果集
results.append({
"comment": comment,
"author": author,
"tagList": tagList
})
return results
# 保存
def on_result(self,result):
if result:
self.save_to_mongo(result)
# 存到数据库
def save_to_mongo(self,result):
if self.db['comment'].insert(result):
print('saved to mongo',result)
|
三 常用方法
auto_recrawl 在任务过期后,自动重爬取
method 请求方法,默认 get 请求
params 追加参数 url, 感觉不常用
data 用于提交 post 请求的数据,可以用于登录?
connect_timeout 连接的超时时间,默认20秒
timeout 超时的请求时间,默认120秒
validate_cert 针对 https 网站,会爆证书错误,设置 false 可以忽略并继续访问,默认true
proxy 代理
etag 布尔类型变量,默认 true, 判断是否发生变化,没有发生变化就不爬了
fetch_type 请求的原始的 docment, 设置 =js 后,就可以调用 js 进行渲染
fetch_type='js'
js_script 可以执行js 操作, 比如滚动到网页的最下端,触发更多加载
1
|
window.scrollTo(0,document.body.scrollHeight);
|
js_run_at 将脚本加入到前面或者后面执行,默认是后面
js_viewport_width/js_viewport_height 视窗的大小
load_images 是否加载图片,默认 false
save 做多个函数之间传递变量,相当于 response 的session
taskid 唯一标识码,去重
四 web 浏览框
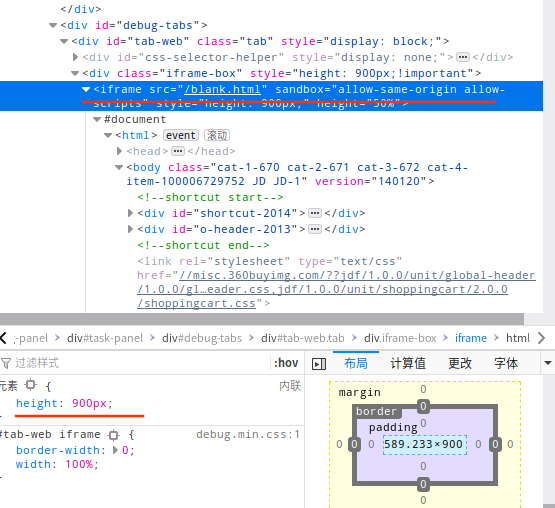
使用的时候发现这个浏览框非常的小, 改变方法见下图2
此方法只能用于本次, 一劳永逸需要修改配置文件
该路径是指向 pyspider 文件夹
sudo vim /usr/local/lib/python3.5/dist-packages/pyspider/webui/static/debug.min.css
增加 iframe 的样式: height:900px !important